

Is The Plural of Anecdote Data?
Is The Plural of Anecdote Data?
How to think about anecdotal information and its relevance to quantified self.

You may have heard the expression “the plural of anecdote is not data”, but it appears that the originator of this expression, political scientist Raymond Wolfinger, actually had said the opposite! The story goes that:
When a student once categorized one of Wolfinger’s claims as “just anecdotal,” he paused for an expectant second, dropping a copy of Robert Dahl’s “Who Governs” onto his seminar table as he replied, “The plural of anecdote is data.”
So, which is it—data or not data? I think that an anecdote usually means an amusing or interesting story. Stories about your everyday normal life aren’t particularly interesting and so they don’t get passed along as anecdotes. Today, I made a cup of coffee. While it might be true, nobody cares to hear more about this. But if I told you today I skydived, you might be a bit more intrigued.
When we want to do the best we can to learn about the world around us, stories aren’t going to cut it; we need to use statistical inference. If we want to study a population, we have to take a sample random sample from that population. From that random sample, we can gain information about the population it was drawn from with statistics. You hear about some statistics in everyday life. The most common one people talk about is the mean. The mean of a variable from a random sample is all the values for the variable summed over the number of observations:
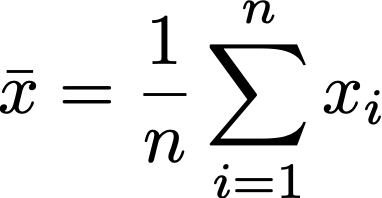
I wouldn’t really care about a sample mean if I could have the population mean, but too often that’s too hard to get. Imagine that I want to know the average height of men in the USA. I could draw a random sample and take the average or I could measure every single man in the USA, but we know that’s not feasible. However, I get really close to that exact population as my sample size gets larger. This is called The Law of large numbers.

The caveat here is that the sample has to be random. If I have a non-random sample, I am not necessarily going to converge on the true mean. In fact, my mean might become more wrong as my sample gets larger if I’m not randomly sampling.
Imagine I run a store that sells fishing gear and periodically when people are searching for their new fishing pole they like to chat with me and tell me stories. Sometimes these stories would involve catching a fish in some spectacular demonstration of fishing skill. I could ask every storyteller how big the fish was and then take an average. Let’s assume these are honest fishers. If I went out fishing, would I expect to catch a fish that was around the average of the length of the fish in the story? No. I didn’t get a random sample!
A bunch of amusing stories would suffer from sampling bias. You only tell a fish story if you caught a big one, otherwise who cares? A better way to figure out how large the fish are in the area is to catch 100 fish and take the average size. We would expect fish to be closer to this average than the average generated from the amazing stories. Of course, me personally catching the fish might be subject to some bias. Maybe, I’m bad at fishing and end up with a bunch of small ones. Even considering these sorts of biases, I would pick my mean over the mean from the shoppers because the sampling process is more random.
I could survey people in a way that is less biased and better even if it is self-reported. Self-reporting is tricky when you have social desirability bias. If you ask someone “how often do you steal?” or “do you cheat on your husband?”, you are not likely to get an accurate representation. People are incentivized to lie. People also aren’t very good at recalling information if you wait too long. Here is a an interesting list of examples of problematic self-reported data.
If I ask someone a straightforward non-political and not morally loaded question related to something that isn’t likely to be forgotten, I can probably get a pretty accurate answer. If I ask “What did you have for breakfast this morning?”, I would expect the answer to be correct. If I ask “Tell me about a breakfast you ate”, they might say something like “Well, this one time when I was in Japan…”.
The problem that people usually have with anecdotes is they will bring it up when presented with data that goes against their experience. If I say that dogs are usually bigger than cats, someone might retort with “Well, I have a really small dog and he is smaller than my cat.” This is an appropriate response if someone says something like “All dogs are larger than cats.” The ambiguity sometimes comes when people say things like “Dogs are larger than cats” which sometimes means all dogs are larger and sometimes means most dogs are larger or somewhere between the two.
The problem is that people will use personal experience and weigh it similarly to a mountain of evidence. That might be okay if the discipline is as poorly replicated as social psychology but generally, we should not weigh empirical evidence more. But what if you don’t have good empirical evidence? Then you might have to use personal experience. Technically, for a Bayesian, an anecdote is data. An anecdote is information that we should use to update our priors. It might be a really really small amount, but technically, it should be incorporated.
Sometimes, we have to use what we know to figure something out. We can’t just go and look up surveys and a bunch of data. We have to think on our feet. If someone said “I will give you $10,000 if you can guess within 10 feet what the average height of trees around you is in the next 15 minutes without using google.” We would have to think of the fly. I wouldn’t really have good priors about tree height—maybe I know trees aren’t a mile tall and aren’t 5 feet tall, but I imagine I’m pretty clueless otherwise.
A good strategy would actually be to go outside and start trying to figure out how tall the trees are. “Well, this one is about 6 feet over a two story building and this one is smaller than this house.” You would want to write it down and then average them up. Of course, this data would likely be biased, but would it be so biased that you shouldn’t use it? I don’t think so.
I think a principle for this is: Absent evidence to suggest otherwise, assume your personal experience is close to average.
If we believe this principle, then personal stories—provided we know they are not amusing anecdotes that are clearly not common—are at least near the average of the population. If we think that, then in the moment reasoning using personal evidence would be somewhat justified.
We have higher standards of rigor for academic studies, but we are often left without the ability to study everything but we need to know information. If we were wondering about whether or not a barber would cut our hair well, we could ask our friend who goes to him. He’s obviously a biased sample, but we are left totally uninformative priors. If we have an N=1 observation, we have some evidence to update.
This question interests me because I have a strong interested in quantified self—the practice of tracking information about yourself. The goal of the tracking is usually to better understand yourself. Some questions that interest me currently are whether or not sleeping more makes me feel better or worse and how biodata like heart rate and heart rate variation relate to mood.
Quantified self is cool because it lets you explore the most relevant conditions for you, namely your own life. I could look up whether or not CBT works to alleviate depressive symptoms and find that it does in a great deal of people, but the best way to figure out if it works for me is to try it. The best way to figure out if something—whether it be exercise, diet, sleep, etc.—works to change you is to measure whatever it is you want to change.
An important question is whether it is worth sharing with others that you had an effect when you made a change or you did not. I think it is. I believe that even a small amount of data is enough to update your beliefs. Usually, if we are exploring some niche area with no prior research, we are clueless. We don’t have a good idea one way or another. A small piece of data is valuable in that regard. If I want to figure out if some sleep pill works well and there is one review online, that is better than no reviews generally. The tricky part is being cognizant of reporting bias.
I have discovered that Nick Bostrom has discovered this principle I devised. He calls it the self-indication assumption: All other things equal, an observer should reason as if they are randomly selected from the set of all possible observers.